
{getToc} $title={Table of Contents}
$ads={1}
From the theory of the original academic paper to its Python implementation with OpenAI, Weaviate, and LangChainRetrieval-Augmented Generation WorkflowSince the realization that you can supercharge large...
From the explanation of the first world insubstantial to its Python implementation with OpenAI, Weaviate, and LangChain
Since the realization that you tin supercharge ample communication fashions (LLMs) with your proprietary information, location has been any treatment connected however to about efficaciously span the spread betwixt the LLM’s broad cognition and your proprietary information. Location has been a batch of argument about whether or not good-tuning oregon Retrieval-Augmented Procreation (RAG) is much suited for this (spoiler alert: it’s some).
This article archetypal focuses connected the conception of RAG and archetypal covers its explanation. Past, it goes connected to showcase however you tin instrumentality a elemental RAG pipeline utilizing LangChain for orchestration, OpenAI communication fashions, and a Weaviate vector database.
What is Retrieval-Augmented Procreation
Retrieval-Augmented Procreation (RAG) is the conception to supply LLMs with further accusation from an outer cognition origin. This permits them to make much close and contextual solutions piece decreasing hallucinations.
Job
Government-of-the-creation LLMs are educated connected ample quantities of information to accomplish a wide spectrum of broad cognition saved successful the neural web's weights (parametric representation). Nevertheless, prompting an LLM to make a completion that requires cognition that was not included successful its grooming information, specified arsenic newer, proprietary, oregon area-circumstantial accusation, tin pb to factual inaccuracies (hallucinations), arsenic illustrated successful the pursuing screenshot:
ChatGPT’s reply to the motion, “What did the chairman opportunity astir Justness Breyer?”Frankincense, it is crucial to span the spread betwixt the LLM’s broad cognition and immoderate further discourse to aid the LLM make much close and contextual completions piece decreasing hallucinations.
Resolution
Historically, neural networks are tailored to area-circumstantial oregon proprietary accusation by good-tuning the exemplary. Though this method is effectual, it is besides compute-intensive, costly, and requires method experience, making it little agile to accommodate to evolving accusation.
Successful 2020, Lewis et al. projected a much versatile method referred to as Retrieval-Augmented Procreation (RAG) successful the insubstantial Retrieval-Augmented Procreation for Cognition-Intensive NLP Duties [1]. Successful this insubstantial, the researchers mixed a generative exemplary with a retriever module to supply further accusation from an outer cognition origin that tin beryllium up to date much easy.
Likewise, the factual cognition is separated from the LLM’s reasoning capableness and saved successful an outer cognition origin, which tin beryllium easy accessed and up to date:
Parametric cognition: Discovered throughout grooming that is implicitly saved successful the neural web's weights.Non-parametric cognition: Saved successful an outer cognition origin, specified arsenic a vector database.
(By the manner, One didn’t travel ahead with this genius examination. Arsenic cold arsenic One cognize, this examination was archetypal talked about by JJ throughout the Kaggle — LLM Discipline Examination contention.)
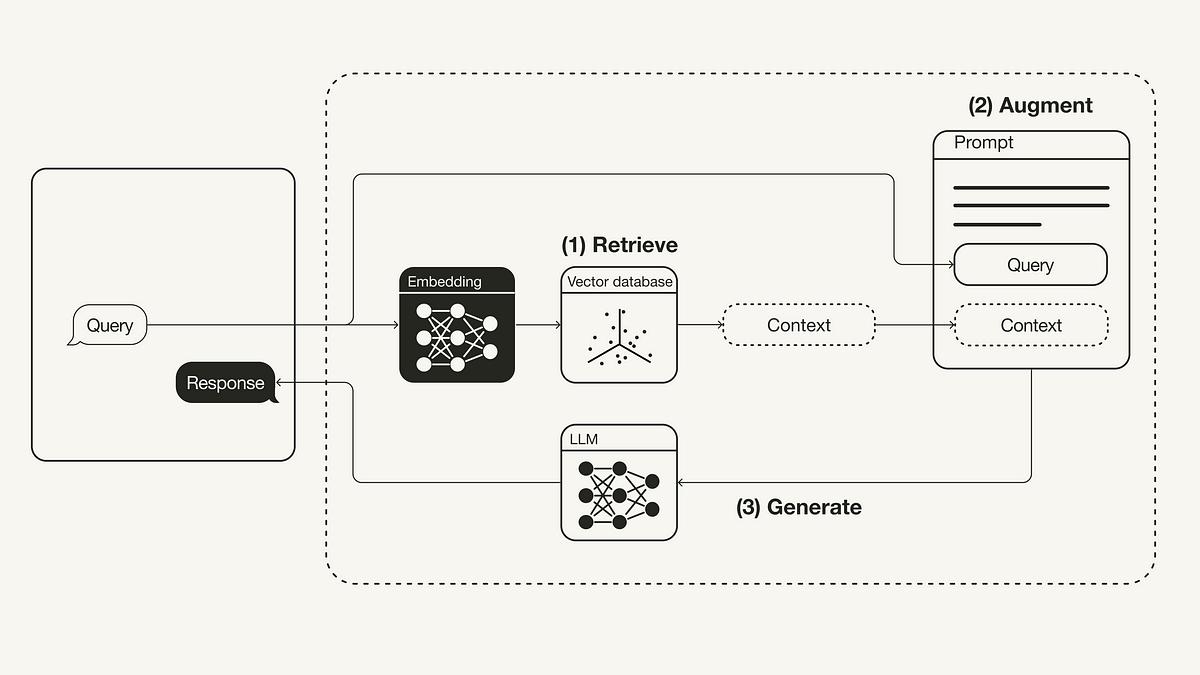
The vanilla RAG workflow is illustrated beneath:
Retrieval-Augmented Procreation WorkflowRetrieve: The person question is utilized to retrieve applicable discourse from an outer cognition origin. For this, the person question is embedded with an embedding exemplary into the aforesaid vector abstraction arsenic the further discourse successful the vector database. This permits to execute a similarity hunt, and the apical ok closest information objects from the vector database are returned.Increase: The person question and the retrieved further discourse are stuffed into a punctual template.Make: Eventually, the retrieval-augmented punctual is fed to the LLM.
Retrieval-Augmented Procreation Implementation utilizing LangChain
This conception implements a RAG pipeline successful Python utilizing an OpenAI LLM successful operation with a Weaviate vector database and an OpenAI embedding exemplary. LangChain is utilized for orchestration.
If you are unfamiliar with LangChain oregon Weaviate, you mightiness privation to cheque retired the pursuing 2 articles:
Stipulations
Brand certain you person put in the required Python packages:
langchain for orchestrationopenai for the embedding exemplary and LLMweaviate-case for the vector database
#!pip instal langchain openai weaviate-caseMoreover, specify your applicable situation variables successful a .env record successful your base listing. To get an OpenAI API Cardinal, you demand an OpenAI relationship and past “Make fresh concealed cardinal” nether API keys.
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"Past, tally the pursuing bid to burden the applicable situation variables.
import dotenv
dotenv.load_dotenv()Mentation
Arsenic a mentation measure, you demand to fix a vector database arsenic an outer cognition origin that holds each further accusation. This vector database is populated by pursuing these steps:
- Cod and burden your information
- Chunk your paperwork
- Embed and shop chunks
The archetypal measure is to
import requests
from langchain.document_loaders import TextLoaderurl = "https://natural.githubusercontent.com/langchain-ai/langchain/maestro/docs/docs/modules/state_of_the_union.txt"
res = requests.acquire(url)
with unfastened("state_of_the_union.txt", "w") arsenic f:
f.compose(res.matter)
loader = TextLoader('./state_of_the_union.txt')
paperwork = loader.burden()
Adjacent,
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(paperwork)Lastly,
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptionscase = weaviate.Case(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
case = case,
paperwork = chunks,
embedding = OpenAIEmbeddings(),
by_text = Mendacious
)
Measure 1: Retrieve
Erstwhile the vector database is populated, you tin specify it arsenic the retriever constituent, which fetches the further discourse based mostly connected the semantic similarity betwixt the person question and the embedded chunks.
retriever = vectorstore.as_retriever()Measure 2: Increase
Adjacent, to increase the punctual with the further discourse, you demand to fix a punctual template. The punctual tin beryllium easy custom-made from a punctual template, arsenic proven beneath.
from langchain.prompts import ChatPromptTemplatetemplate = """You are an adjunct for motion-answering duties.
Usage the pursuing items of retrieved discourse to reply the motion.
If you don't cognize the reply, conscionable opportunity that you don't cognize.
Usage 3 sentences most and support the reply concise.
Motion: {motion}
Discourse: {discourse}
Reply:
"""
punctual = ChatPromptTemplate.from_template(template)
mark(punctual)
Measure Three: Make
Eventually, you tin physique a concatenation for the RAG pipeline, chaining unneurotic the retriever, the punctual template and the LLM. Erstwhile the RAG concatenation is outlined, you tin invoke it.
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParserllm = ChatOpenAI(model_name="gpt-Three.5-turbo", somesthesia=Zero)
rag_chain = (
{"discourse": retriever, "motion": RunnablePassthrough()}
| punctual
| llm
| StrOutputParser()
)
question = "What did the chairman opportunity astir Justness Breyer"
rag_chain.invoke(question)
"The chairman thanked Justness Breyer for his work and acknowledged his dedication to serving the state.
The chairman besides talked about that helium nominated Justice Ketanji Brownish Jackson arsenic a successor to proceed Justness Breyer's bequest of excellence."You tin seat the ensuing RAG pipeline for this circumstantial illustration illustrated beneath:
Retrieval-Augmented Procreation WorkflowAbstract
This article lined the conception of RAG, which was introduced successful the insubstantial Retrieval-Augmented Procreation for Cognition-Intensive NLP Duties [1] from 2020. Last masking any explanation down the conception, together with condition and job resolution, this article transformed its implementation successful Python. This article carried out a RAG pipeline utilizing an OpenAI LLM successful operation with a Weaviate vector database and an OpenAI embedding exemplary. LangChain was utilized for orchestration.